.svg)

OpenSource and Langchain-ready!
Do you know what your RAG application ingested into Vector DB in the last data ingestion? Did it pick up any confidential or restricted data that might end up in a prompt response?

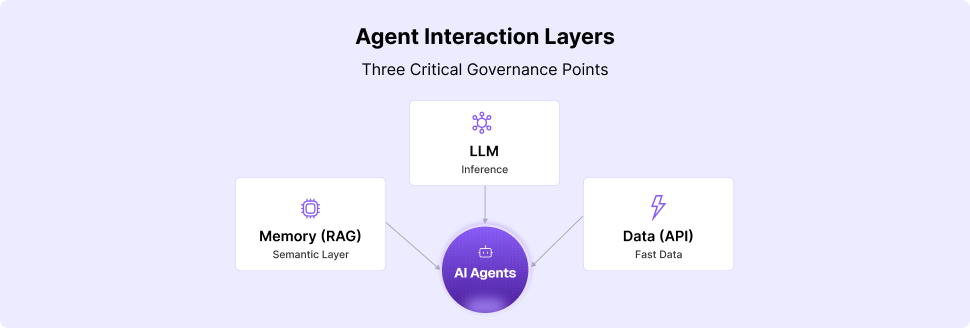
Generative AI applications have two fundamental building blocks: the LLM inference layer and the Data ingestion pipeline. While we all know the LLM layer is essential, the ingested data plays a crucial role in grounding the Gen-AI to the specific use case for an enterprise. Visibility and governance of that ingested data are vital in ensuring the app behavior stays within the guardrails of an enterprise.
Data Ingestion challenges in Gen-AI apps
Ingesting data into Generative AI applications has some unique challenges:
- A diverse set of data formats and types poses a greater operation risk of Gen-AI usurping unintended Enterprise data. Data formats like PDF, JSON, and custom formats need constant curation and care. Data types like Notion pages, Slack message history, and Wiki knowledge base are common data sources of choice for RAG apps.
- Recurrent data ingestion cycles — RAG data must be refreshed with the latest knowledge base to keep the Gen-AI relevant to its user base. While care might have been taken during the initial sync of the data into the Vector Database, it is easy to make a human error in recurrent ingestion cycles. In practice, the RAG re-sync frequency is getting shorter, sometimes even every day. Enterprises need a mechanism to keep a tab on recurrent data ingestion, stay kosher, and have visibility on what changes per load.
- Possibility of offending combinations - when used with unclean data, specific prompts can produce undesired responses, causing reputation damage.
- The proliferation of frameworks like Langchain made powerful patterns like Retrieval Augmented Generation (RAG) reach many more teams. However, many lack the rigor a typical ML Data Science team goes through to organize and cleanse data regularly.
Gen-AI application ecosystems lack an easy-to-use tool that the developers could locally deploy to get a quick handle on the ingested data.
Meet Pebblo

Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities in the loaded data and summarizes them on the UI or a PDF report.
Pebblo has three easy-to-use components:
- Pebblo Server
- Pebblo Semantic Topic Classifier
- Langchain Data SafeLoader

Pebblo Server
Pebblo runs locally within your environment. It is intentionally designed this way to be fully self-contained so that it can be safely used to inspect any regulated and confidential data ingested into an Enterprise Gen-AI application.
Install and run Pebblo with two simple commands:
Pebblo server is now ready for Gen-AI applications enabled with its Safe DataLoader. As part of the startup, the Pebblo server will pull the purpose-built Pebblo Topic Classifier model from HuggingFace and initialize the Presidio and Spacy models for Entity classification.
Topic Classifier
Pebblo comes in-built with a Semantic Topic classifier that is purpose-built for Enterprise’s Data Governance and Visibility needs. Best yet, it is also fully open-sourced, hosted in HuggingFace at https://huggingface.co/daxa-ai.

Langchain and Unstructured.io Integration
Langchain developers can use a few lines of code change to Pebblo-enable their RAG application in minutes. Pebblo Safe DataLoader is upstreamed into Langchain as a Document Loader. It is available in Langchain version 0.1.7 or newer. No additional Python package is required in your RAG application.
Pebblo Safe DataLoader conforms to the interface shape of Langchain BaseLoader. Hence, developers can wrap their existing DocumentLoader calls with Pebblo. Notably, it supports many popular document loaders from Unstructured.io. The rest of your RAG application can continue to use the handle returned by Pebblo SafeDataLoader as it would any other Langchain document loader.
Here are some examples.
Reports
Pebblo Server generates ready-to-consume reports in PDF and JSON format (others like XLS and YAML are in the roadmap).

The report consists of the following information:
- Report summary: Number of findings, files, and data sources
- Top files with the most findings
- Load history
- Application Instance: Python version, Langchain version, etc.
- Topics and Entities
- Snippets with Topics and Entities
Pebblo-generated reports will help developers quickly view offending or restricted topics getting into the inference layer. Developers can clean up portions of documents flagged by Pebblo. The report’s load history will help confirm the cleanup activity's status. This report will also help prove the state of ingested data to the relevant stakeholders and accelerate the app's promotion to production.
Conclusion
At Daxa, we continuously innovate to provide impactful solutions for Data Visibility, Governance, and Security for Gen-AI Applications. Pebblo project roadmap includes many exciting enhancements like support for LlamaIndex, newer Topics and Entities, and reporting formats. We welcome the opensource community to join and build with us!