.svg)

Bringing identity and authorization as a first-class citizen to the Gen-AI application using Langchain, Unstructured.IO, and Pebblo by Daxa
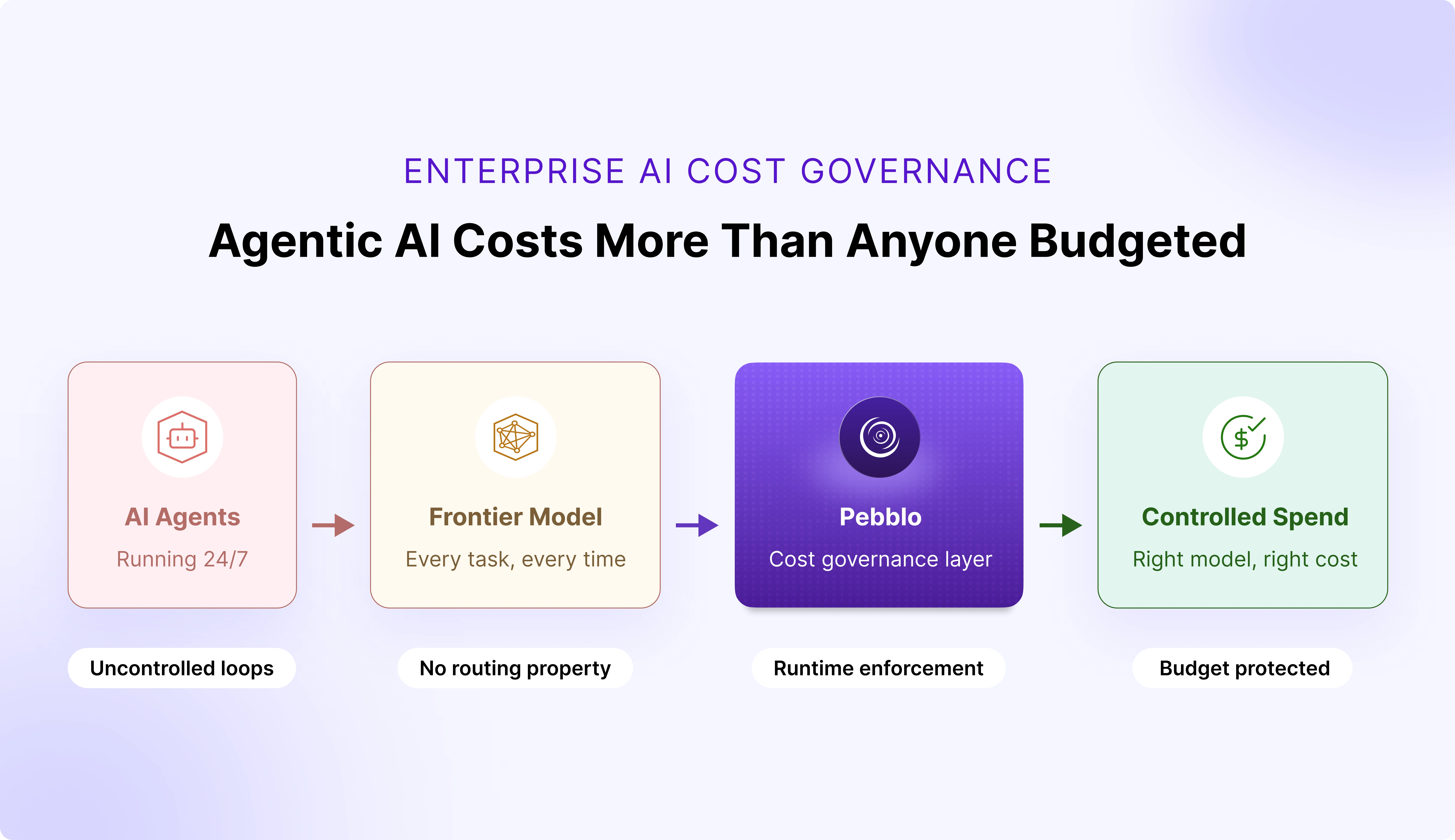
Identity played a secondary role in the inner workings of a Gen-AI application — document loading, chunking, and retrieval. Today’s Gen AI apps largely rely on the scope of their applications to limit the authorized users. For example, an AI-enabled HR chatbot with confidential HR documents would limit access to only the HR employees, an AI-enabled Finance app to the employees in the finance department, an AI-enabled Legal app to the legal department, and so on and so forth.
The challenge is even more pronounced when the same application needs to exclude some documents for specific users. One of our customers' internal productivity apps is required to provide full document access to employees but limit some documents for contractors. The lack of this identity and authorization enforcement, combined with extreme caution in handling data, forced Gen-AI architects and developers to resort to creating separate apps for each scenario. This approach leads to a proliferation of many AI-enabled internal apps with overlapping functionality, administrative nightmares, increased development and deployment costs, and maintenance challenges.
How can we solve this? We need three things,
- Identity-aware Data Ingestion
- Vector Database with identity metadata filtering
- Retrieval with Identity & Semantic Enforcement

Identity-aware Data Ingestion
Data ingestion into Vector databases is typically done using document loaders from Unstructured.io and others in Langchain. This solution proposes to host the documents in an identity-aware document repository. This way, the documents are marked at the source who is authorized to access them. While we illustrate this solution using Google Drive, any authorization-capable document storage will work, including Sharepoint (with ActiveDirectory DACLs) and Snowflake.
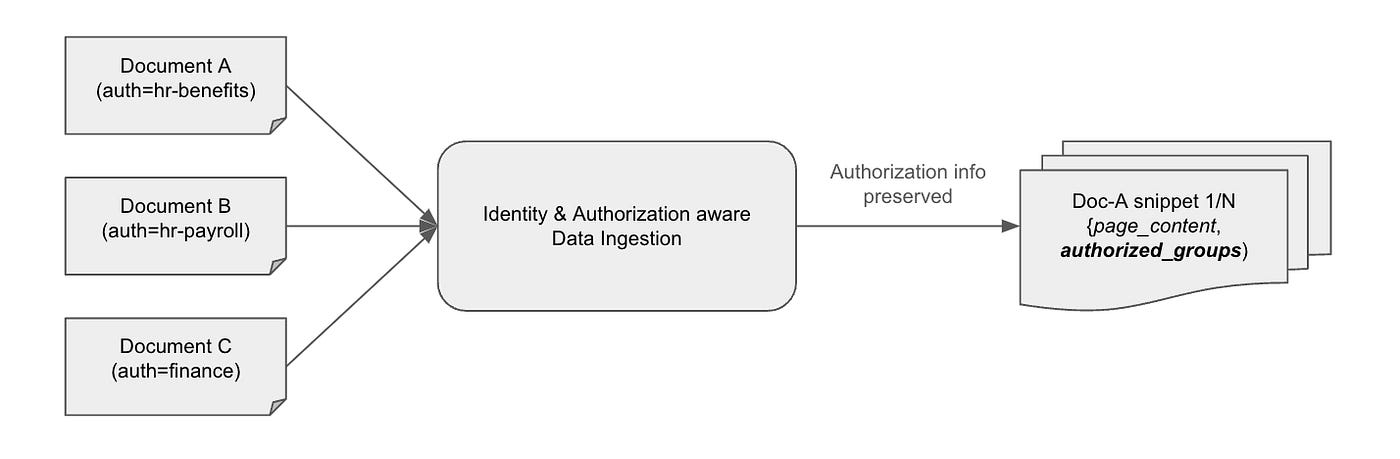
There are two common ways the data is prepared for Gen-AI purposes.
- Identify documents in the enterprise document stores and point the document store loaders toward them for data ingestion. In this option, we propose enhancing the loaders to pull document authorization details along with the actual document. GoogleDriveLoader is the first of many to get authorization enabled.
- Use an ETL process to extract documents from data sources into a single data repository. For a single application, the documents could come from multiple sources — knowledge base, product sheets, and multiple types — PDF, Markdown, etc. In this option, we propose enhancing the ETL process to extract the document authorization level along with the actual document and store both in an authorization-aware target data repository. This makes the Gen-AI ETL process now identity and authorization aware!

One leading commercial offering in this GenAI-ETL space is the Unstructured Enterprise Platform. Building on their rich set of open-source document loaders, Unstructured.IO’s platform automates connecting to various data sources, loading, chunking, and ingesting of Identity-aware snippets into the Vector database.
Vector Database with Authorization Metadata
Vector DB is the intermediary that stands in between data ingestion and retrieval. Many Vector databases support search with metadata filtering. Some of the popular ones with this support are Pinecone, Postgres PGVector, and OpenSearch. This solution enhances the Document Loading process to capture the authorization information of the source document into specific fields in the metadata of the VectorDB entry of each of the chunks.
{
{
"page_content": "Employee leave-of-absence policy ...",
"authorized_identities": ["hr-support", "hr-leadership"],
...
"category": "NarrativeText",
"source": "https://drive.google.com/file/d/1Wp../view",
"title": "hr-benefit-guide-38.pdf",
},
{
"page_content": "total comp for senior staff ranges from ...",
"authorized_identities": ["hr-leadership"],
...
"category": "NarrativeText",
"source": "https://drive.google.com/file/d/1Gk../view",
"title": "hr-payroll-exec-comp-2023-Q4.pdf",
},
}Note: Vector DB has now become another authorization enforcement point. Care must be taken to deploy vector database instances with the same security posture and guardrails as the original document source.
With authorization info in the Vector DB metadata, the Gen-AI retrieval layer can use filtering to extract only the documents allowed for specific authorized groups.
Here is an example using Pinecone:
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("pinecone-index")
index.query(
vector=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
filter={
"authorized_identities": {"$in": "hr-support"},
},
top_k=3,
include_metadata=True
)Retrieval with Identity & Semantic Enforcement
We are introducing PebbloRetrievalChain for semantic topics and identity authorization enforcement.
PebbloRetrievalChain uses a SafeRetrieval to enforce that the snippets used for in-context are retrieved only from the documents authorized for the user and semantically aligned to the application. To achieve this, the Gen-AI application needs to provide an authorization_context for this retrieval chain. This auth_context should be filled with the identity and authorization groups of the user accessing the Gen-AI app.
# Authenticate user to get auth_context
auth:dict = {"authorized_groups": ["hr-support"]}
# Semantic policy
semantic:dict = {"deny": ["toxic", "bias", "confidential"]}
# Prepare retriever QA chain
llm = OpenAI()
chain = PebbloRetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
auth_context=auth,
semantic_context=semantic,
vector_db = self.vectordb.as_retriever(),
)Conclusion
Identity enforcement is key to the successful deployment of trusted Gen-AI applications in Enterprises. While some solve this with custom, bespoke DIY implementation, the solution described in this blog with Unstructured.io, Langchain, and Pebblo by Daxa AI coming together in this ready-to-adopt cookbook will help teams to quickly adopt identity into the Gen-AI application behavior. It will help Gen-AI leaders, architects, and developers to take their use cases confidently to their user base without the fear of inadvertently leaking restricted information to unauthorized users.
References
- Pebblo GitHub — https://github.com/daxa-ai/pebblo/
- Pebblo Website — https://www.daxa.ai/pebblo
- Unstructured Enterprise Platform — https://unstructured.io/platform
- Pinecone filtering with metadata — https://docs.pinecone.io/docs/metadata-filtering