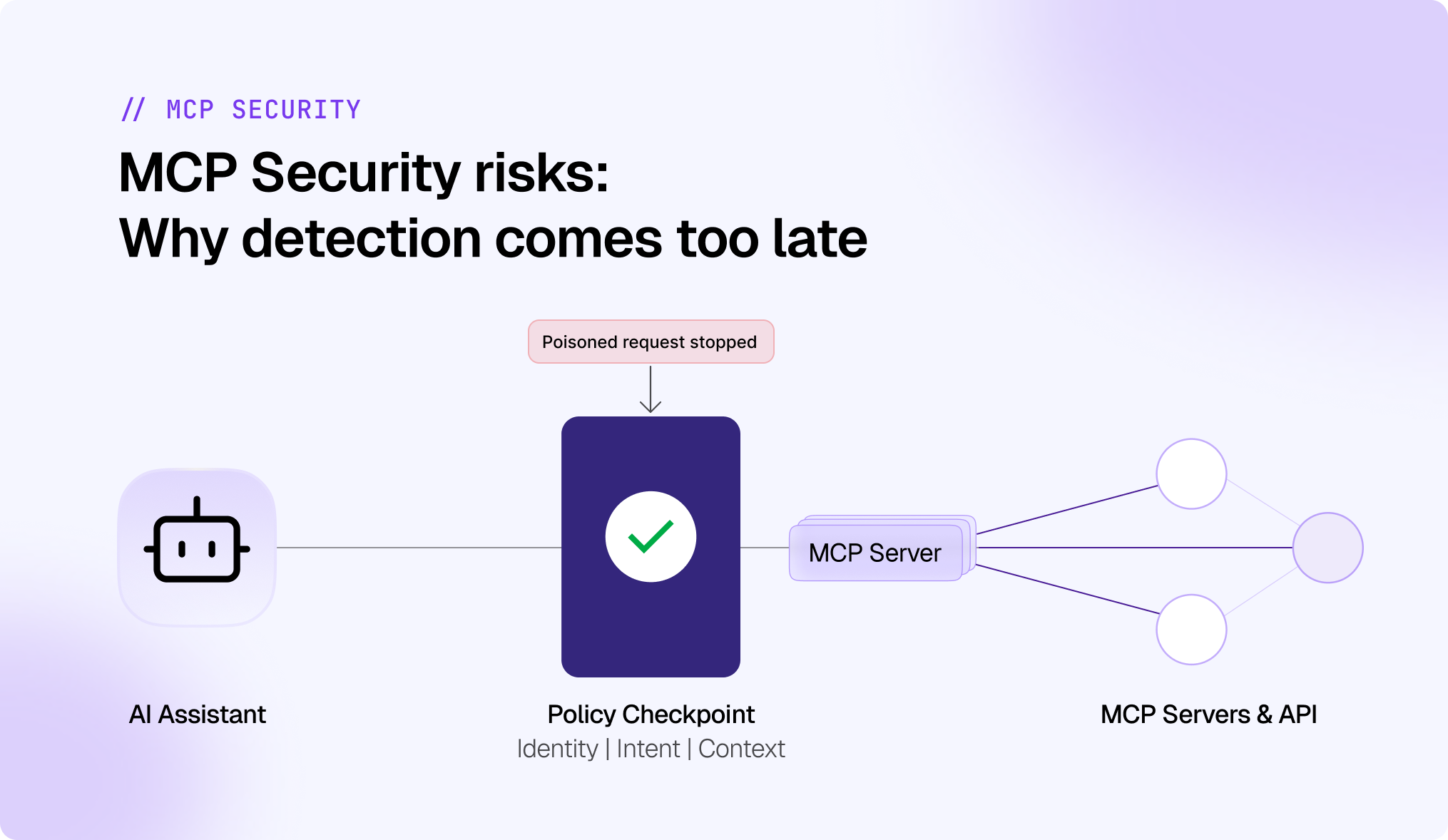
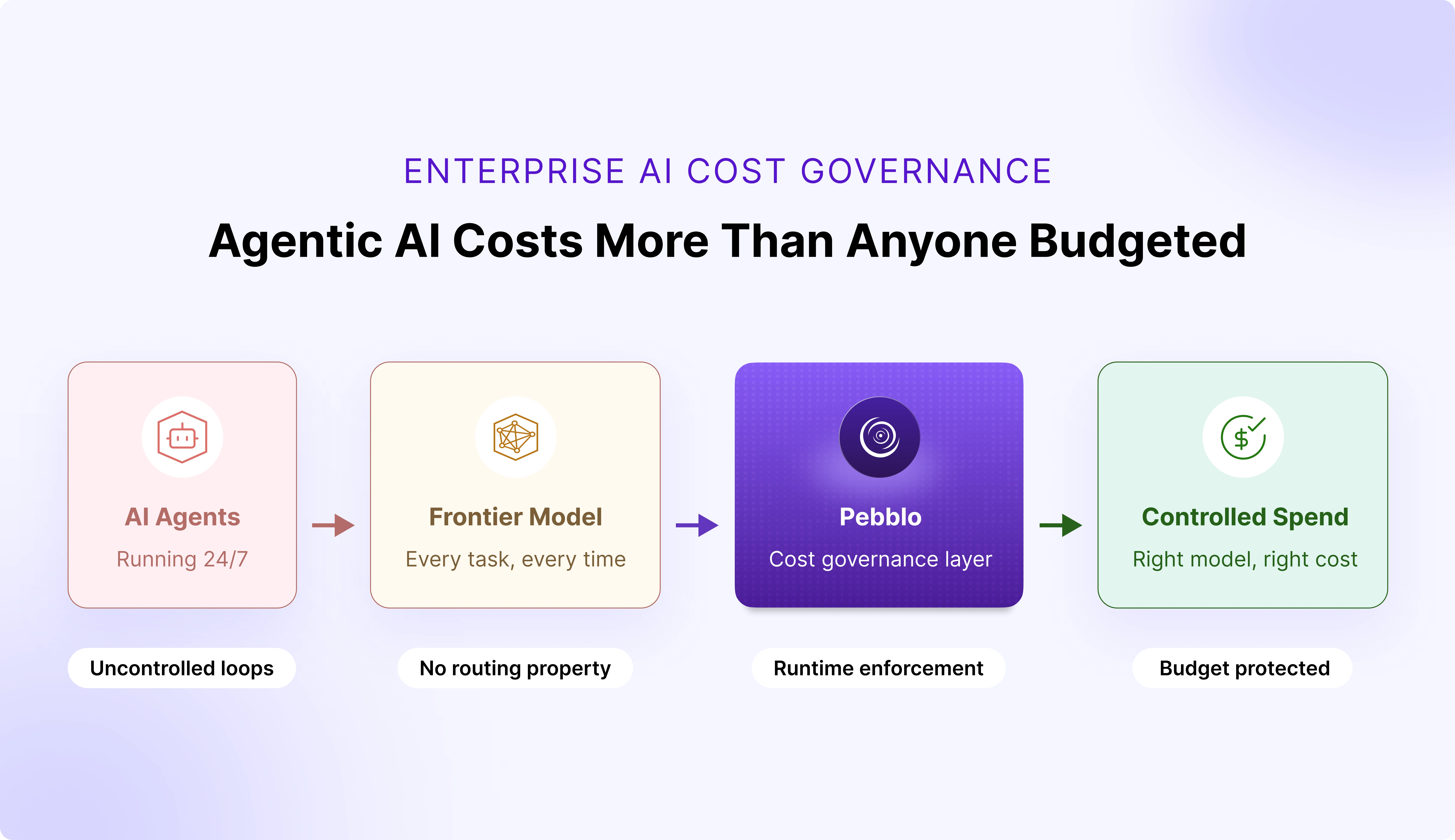
.svg)

Imagine this: It’s a typical Monday morning in an enterprise where data flows like rivers, spanning across SharePoint, Google Drive, Slack, and more. An engineer sits down, enters a query into the company’s cutting-edge AI-powered enterprise search tool, and, like magic, instead of retrieving a list of documents, it generates a detailed response synthesized from multiple sources. They get their answers faster than ever, productivity soars, and the engineer can focus on solving real problems instead of hunting for information. Sounds perfect, right?
But lurking beneath this transformative productivity lies a troubling question: What if that engineer, in their search for an answer, stumbles across next quarter’s confidential financial forecast? Or, even worse, proprietary intellectual property not meant for their eyes? Welcome to the double-edged sword of Generative AI-powered enterprise search at once the hero and the potential villain of the modern enterprise.
How Generative AI Reshaped Enterprise Search
Enterprise search is nothing new. For years, organizations have been trying to build tools to find answers across their sprawling knowledge bases. But let’s face it traditional search engines struggled to make sense of unstructured data. Generative AI changed the game. By leveraging dense vector embeddings, graph-based reasoning, and Retrieval-Augmented Generation (RAG), AI could finally retrieve and synthesize information in context, making it smarter and more intuitive than ever before.
This innovation unlocked massive benefits: cross-departmental productivity gains, seamless integrations with workflows, and the promise of a virtuous cycle of efficiency. Enterprise search tools evolved from static information retrieval systems into intelligent answering and actioning engines. But this transformation also created new risks ones that could potentially undo all the progress.
One Basket, Too Many Eggs
The magic of enterprise search lies in its ability to connect with a vast array of data sources: from document repositories like Google Drive and SharePoint to conversations in Slack, tickets in ServiceNow, and everything in between. Yet, bringing all this data under one umbrella also creates a centralized risk point.
Consider this: A summer intern with legitimate access to Slack conversations could, without the right controls, inadvertently gain access to sensitive financial documents that weren’t meant for their eyes. Or imagine a HR manager querying for “employee termination guidelines” but ends up receiving a response based on wrongful termination lawsuits stored in a shared repository simply because those files weren’t meticulously locked down.
Why Identity Authentication Isn’t Enough
Most enterprise search tools today rely on identity-based access controls tied to Identity Providers (IdPs). These systems authenticate users and grant access to documents based on predefined permissions. While this sounds robust in theory, the reality in most enterprises tells a different story.
In the vast majority of organizations, permissions are often mis-provisioned, leading to over-permissioning or inconsistent access controls. Why? Because enterprise data spans across disparate systems, managed by different teams, and governed by varying policies. Permissions that might have been meticulously set when the system was first implemented often become outdated or irrelevant over time as employees switch roles, projects evolve, or new tools are integrated.
The result? Even with strict identity authentication, users often end up with access to data they shouldn’t see. Generative AI tools, by connecting siloed data and surfacing results across all repositories, shine a glaring light on these over-provisioning issues. They effectively dismantle the illusion of security-by-obfuscation, making it alarmingly easy to discover or stumble upon exposed information. The user only needs to formulate a query and GenAI will do the rest.
Beyond Identity: Understanding Document, User, and Application Intent
Relying solely on identity-based access controls assumes a perfectly provisioned, centralized environment where permissions are clear-cut and enforced uniformly. But the reality for most enterprises is far messier, leading to inconsistent protections that crumble when mirrored by Gen AI powered enterprise search tools.
The challenge isn’t just about determining who can access a document it’s about understanding the context. Why does the document exist, what purpose does it serve, and how should it be accessed? This is where intent spanning document, user, and application becomes critical. Let’s explore how these dimensions intersect to redefine access control:
1. Document Intent: Who was this document intended for? This isn’t always tied to an IdP it could be based on the document’s semantic context, its confidentiality level, or compliance regulations like HIPAA or GDPR. A static access control list isn’t enough to address these nuanced needs.
2. User Intent: Why is this user asking the question? Is their intent aligned with their role or permissions? For example, a junior sales rep asking a question about “company forecasts” might be blocked from accessing financial projections, even if the document permissions allow access.
3. Application Intent: What is the purpose of this Gen AI application in this organization? For instance, if the enterprise search tool is intended to enable productivity within the engineering team, it should prioritize engineering-related results while blocking access to irrelevant or sensitive business documents.

Together, these three dimensions demand a more sophisticated form of access control one that goes beyond static permissions and enters the realm of reasoning-driven access control. This is where the TwinGuard architecture comes in, with two distinct layers working in tandem.
- Data Ingestion Gateway
Every piece of data coming into the application should be semantically classified on-the-fly. Is this document confidential? Does it fall under GDPR or HIPAA compliance? These attributes, along with access control and lineage information, need to be tagged dynamically and stored with the document. Certain documents can be filtered out at this stage itself for example, those with harmful or biased content.
2. User Access Gateway
At retrieval time, the system should evaluate the user’s query and identity against the access control, lineage, and semantic tags, along with the application’s context to decide what information to surface in the response and what to block. By considering the intents of the user, document, and application, this stage enables reasoning-driven enforcement.
Key attributes of the TwinGuard architecture:
- Developer-Friendly Integration: For these controls to be effective, they must be developer-centric and align with the application’s unique context user, data, and task positioning the application as the ideal enforcer of precise, reasoning-driven access controls.
- Retrieval-Agnostic Governance: Whether the enterprise search tool uses sparse (BM25), dense vectors, graph-based retrieval, or an agentic RAG system, these controls must work seamlessly across all methods. After all, the risks we’ve discussed apply universally, regardless of the retrieval architecture.

How It All Comes Together
Let’s revisit the HR manager example. The manager queries “employee termination guidelines,” and without safeguards, the system generates an answer that incorporates sensitive legal memos about wrongful termination lawsuits. Here’s how TwinGuard prevents this:
1. Data Ingestion Gateway: During ingestion, the legal memos are tagged as “legal material” and marked as sensitive, ensuring they are flagged as inappropriate for use outside the legal team.
2. User Access Gateway: When the HR manager’s query is processed, the gateway evaluates the query, the manager’s role, and the application’s intent (focused on HR policies). The legal memos are suppressed even though they are accessible to the manager’s role and the system retrieves only the relevant HR guidelines to generate the response.
By reasoning across data, user, and application intents, TwinGuard ensures that GenAI-powered responses are safe, context-aware, and compliant, addressing risks that identity-based controls alone cannot mitigate.
The Path Forward
As generative AI continues to shape the future of enterprise search, it’s clear that data governance must evolve in parallel. Without safeguards, enterprises risk exposing sensitive data, violating compliance regulations, and eroding trust in these transformative technologies.
By embedding context-aware controls directly into GenAI workflows, organizations can balance innovation with robust governance. As enterprises embrace GenAI, architectures like TwinGuard help ensure that its potential is unlocked with care and precision. The question isn’t just whether GenAI can deliver answers it’s whether those answers are delivered securely, responsibly, and in alignment with enterprise ethics.